
Aktuell drehen sich viele Diskussionen in der Data Community um das Thema Datenkompetenz, das auch mit dem Schlagwort „Data Literacy“ bekannt geworden ist. Da stellt sich natürlich jeder die Frage: Bin ich „data literate“?
Aber was heißt das eigentlich data literate zu sein? Laut Gartner spiegelt sich in Datenkompetenz vor allem der sichere Umgang mit Daten und zielgerichteter Einsatz von Daten im Arbeitsalltag wieder. Dazu gehört nicht nur das Verständnis der vielen Unternehmensdaten, sondern auch die datengestützte Entscheidungsfähigkeit einer Organisation. Auf Individueller Ebene bedeutet es auch eine hohe Motivation zu haben, mehr über Daten und ihre Entstehung zu lernen, diese auf Nutzung sowie Qualität zu bewerten und datengestützte Prozesse zu etablieren.
Warum ist es wichtig?
Daten sind überall. Gepaart mit den neuesten Fortschritten in der Künstlichen Intelligenz scheint uns die Welt der Daten mit intelligenten Anwendungen, wie ChatGPT, schon fast zu entgleiten. Unternehmen müssen bewusster mit Daten umgehen und dabei ist die Datenkompetenz einzelner Mitarbeiter ein entscheidender Treiber.
Ganz schön viel für eine Person, oder? Wie schafft man es als Organisation diesem Anspruch gerecht zu werden?
Vor allem die Data Culture und die Befähigung von Mitarbeitern zum richtigen Umgang mit Daten steht dabei im Vordergrund. Neben den auf der Hand liegenden Maßnahmen, wie dem Aufbau einer Data Academy oder Förderung der Data Community, kann das Metadatenmanagement als wesentlicher Treiber zum Aufbau der Datenkompetenz genutzt werden.
Metadaten enthalten wertvolle Informationen zu Daten, wie ihre Definition und Verarbeitung, aber auch zur Qualität sowie Schutzbedürftigkeit von Daten. Mit einem breiten Einsatz von Metadaten können enorme Potentiale für die Datenkompetenz entfaltet werden, die sich vor allem mit einem Data Catalog unternehmensweit verankern lassen.
Wie lassen sich die Mehrwerte eines Data Catalogs für die Datenkompetenz an einem konkreten Beispiel aufzeigen?
Klaus Henning arbeitet im Bereich Einkauf & Beschaffung und muss aufgrund neuer ESG-Regularien reporten, ob aus Sicht des Beschaffungsprozesses Nachhaltigkeitsziele des Unternehmens erfüllt sind. Nachhaltigkeitskennzahlen sind eine zentrale Entscheidungsgrundlage für bspw. zukünftige Investitionen und bestimmen massiv die Strategie des Unternehmens.
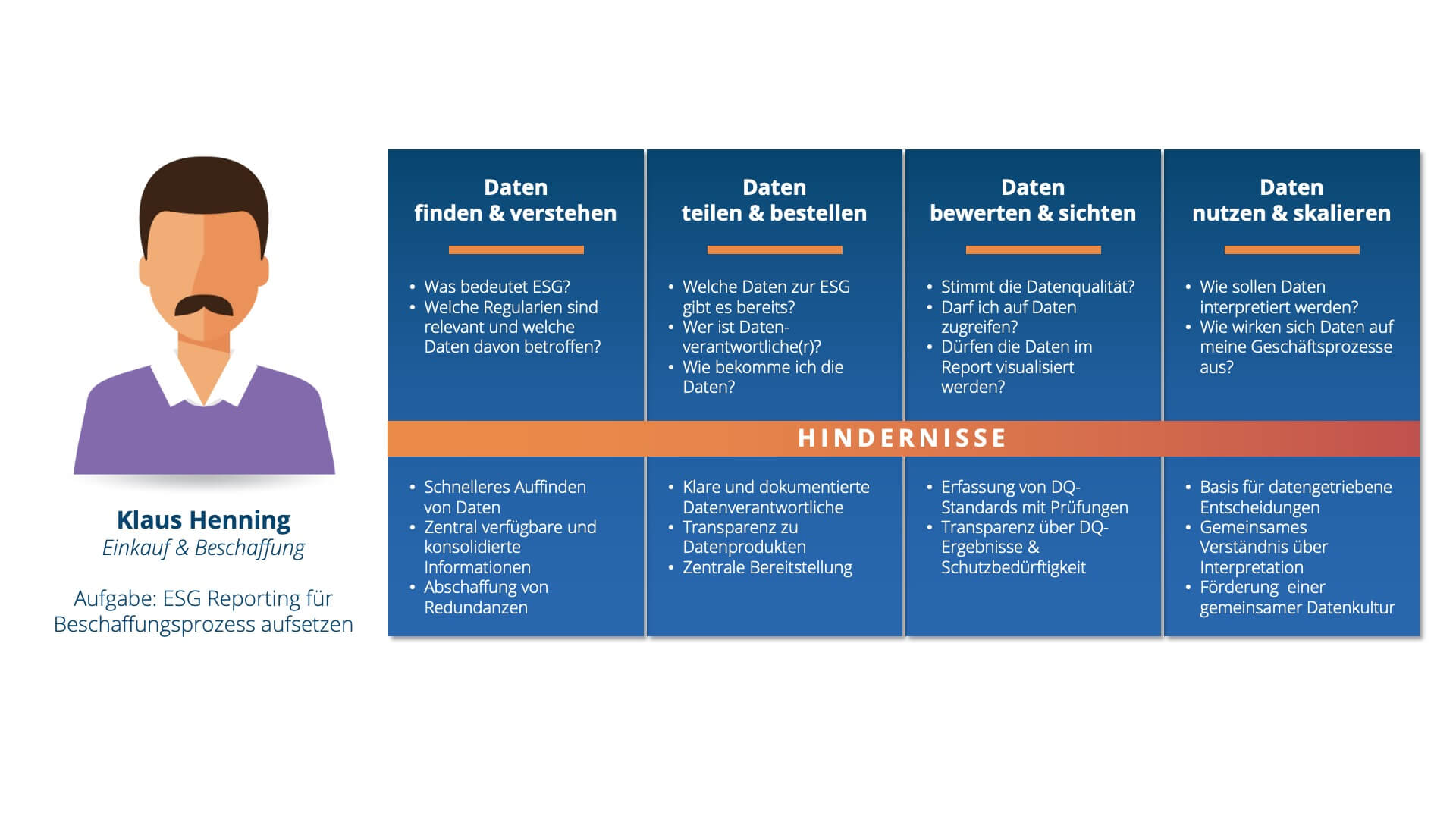
Das Thema ESG ist sehr neu, d.h. nur wenige KPI’s werden bereits reportet. Auch Klaus hat im Kontext der Beschaffung noch keine Expertise aufbauen können und hat viele Fragen rund um das Thema ESG.
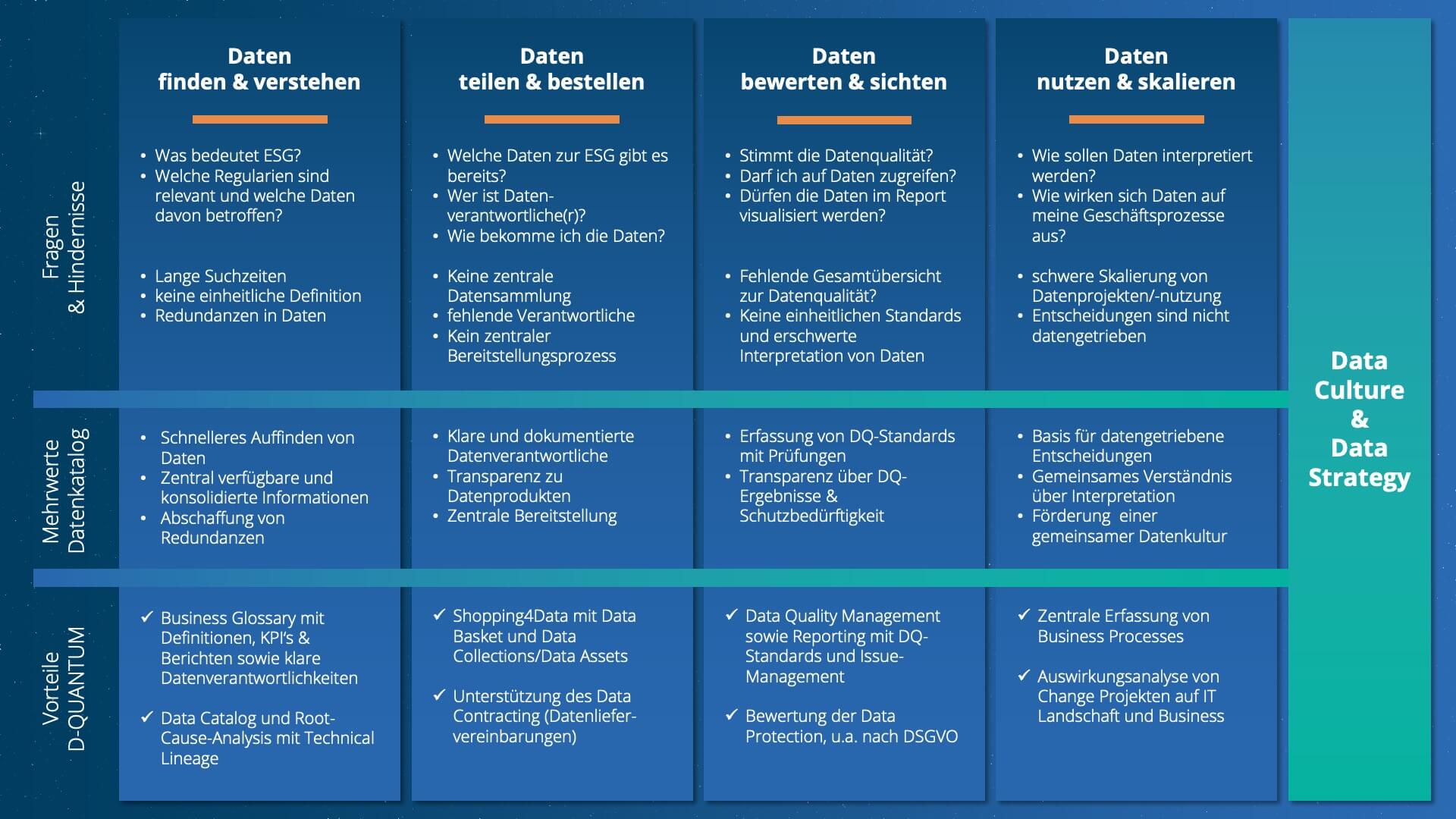
Über einen Data Catalog kann Klaus recherchieren, welche Informationen zu ESG bereits dokumentiert sind, ob es bereits vorhandene Kennzahlen bzw. Reports gibt und sogar über D-QUANTUM Zugang zu relevanten Daten bestellen. Er kann außerdem Lücken identifizieren und Quellsysteme finden, die für die Implementierung eines ESG-Reportings geeignet sind. Zusammenfassend lässt sich ein Data Catalog vielschichtig zur Unterstützung der Data Literacy einsetzen. Angefangen bei der Schaffung von Grundlagen für das Datenverständnis bis hin zur Analyse und Qualifizierung von Datenquellen wirkt ein Data Catalog mit dem richtigen Einsatz als Enabler der Datenkompetenz.
Ein Data Catalog bleibt jedoch ein Tool, das einen richtigen Einsatz erfordert. Für den Erfolg von Data Literacy Maßnahmen, auch auf organisatorischer Ebene, ist und bleibt der Mensch von zentraler Bedeutung.


